Introduction
In our previous article, we delved into the intricacies of structuring our database using the power of Mongoose. Today, we will discuss a crucial architectural pattern that will elevate how you think about and interact with your data: The Data Access Object (DAO) Pattern.
The DAO pattern is a useful way to organize our database operations, but MongoDB also offers much flexibility in querying. This article will start by explaining the importance and benefits of the DAO pattern. Then, we will explore MongoDB queries in detail, showing how they can help us manipulate and retrieve data more effectively.
The Data Access Object Pattern
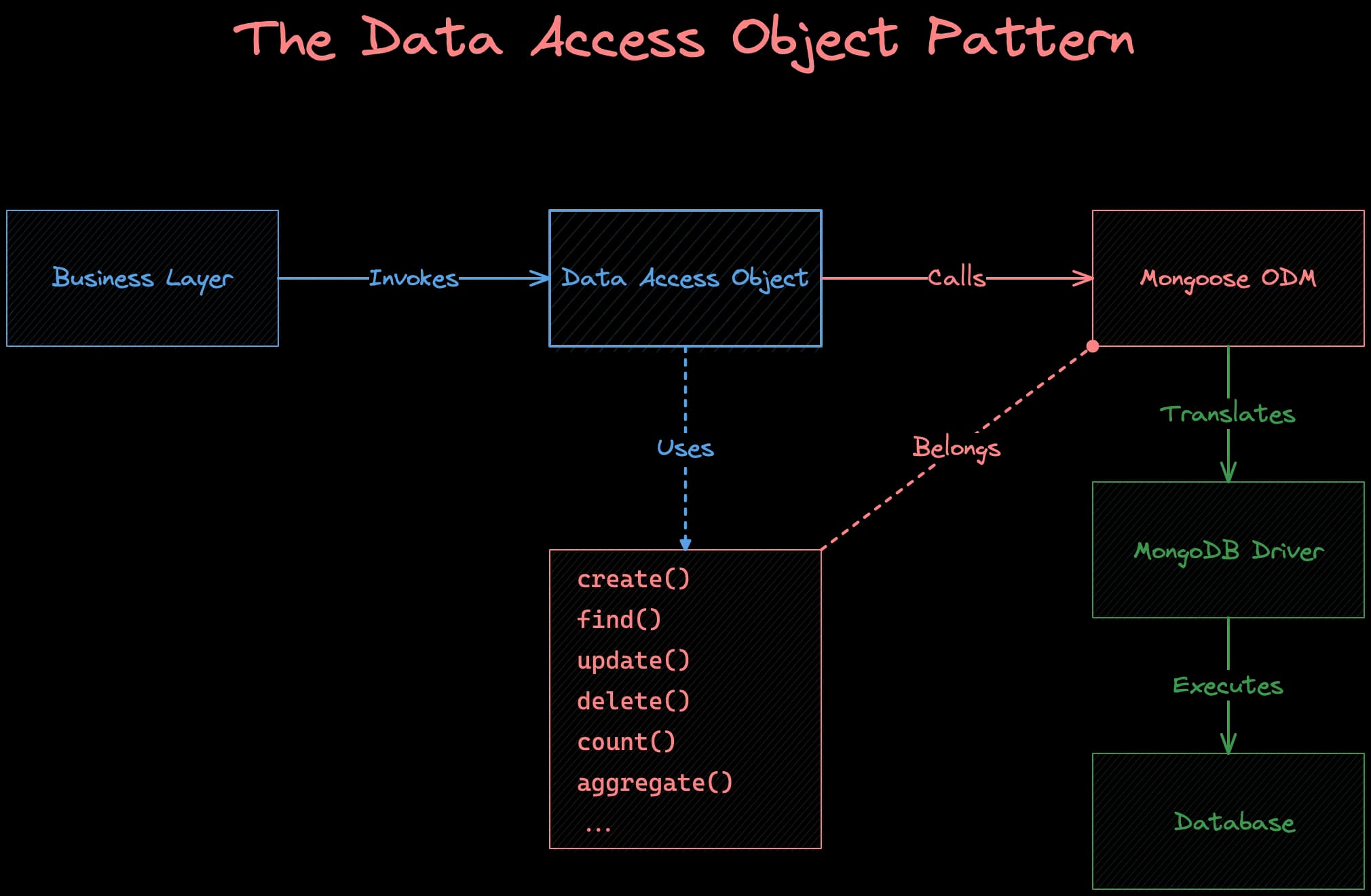
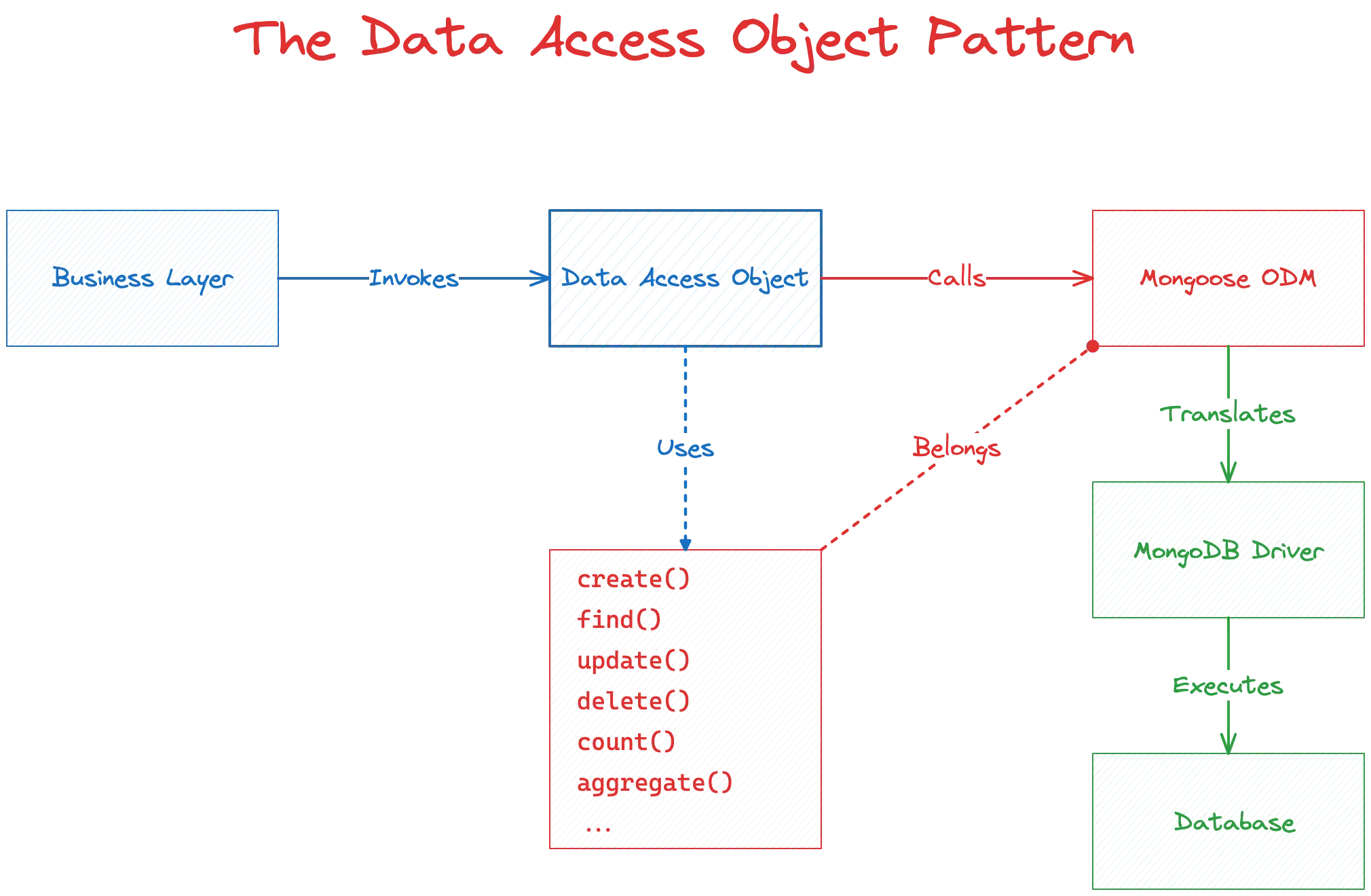
The Data Access Object Pattern is a design approach to abstract and encapsulate all access to data sources. It manages the connection with the data source to obtain and store data. The purpose of the DAO pattern is to separate the persistence logic from the business logic, enabling the system to be more scalable, maintainable, and flexible.
There are typically a few components involved with each interaction with the database:
- Business Layer: This is the level where all the business rules and logic reside. The business layer interacts with the DAO to achieve data persistence or retrieval without knowing how and where the data is stored.
- Data Access Object (DAO): At the heart of this pattern, the DAO is responsible for abstracting access to data. It provides methods to perform CRUD operations, ensuring that the business layer isn't concerned with how the data is stored or retrieved. This abstraction is essential to the DAO pattern as it enables changes to the data source/storage mechanism without affecting business logic.
- Mongoose ODM: Serves as the bridge between our DAO and the MongoDB database driver, providing the necessary methods and mechanisms for data operations.
- MongoDB Driver: This is the underlying driver that Mongoose uses to interact with the MongoDB database. It translates high-level operations into actions the MongoDB database can understand and execute.
- Database: The final layer where the data is stored. The MongoDB driver communicates directly with the database, executing operations and returning results as necessary.
This flow ensures a clean separation of concerns, where each layer is responsible for its distinct task. This pattern can lead to a cleaner, more maintainable, and scalable codebase when implemented well.
To exemplify the DAO pattern in action, create a new dao.ts file inside the project folder:
import Project, { IProjectDocument } from './model';
import { Model } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
}import Project, { IProjectDocument } from './model';
import { Model } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
}Here, we define a ProjectDAO class specific to the Project model. The class encapsulates the Mongoose model for projects. This design promotes clean code and ensures that any changes to the database or its structure have minimal ripple effects on the rest of the application. By incorporating the DAO pattern, you can ensure that the business logic remains unaffected by data storage or retrieval mechanism changes.
Model-Level VS. Document-Level Queries
While working with MongoDB using Mongoose, you will encounter two primary types of queries: model-level and document-level. Both have unique roles in CRUD operations. Understanding the difference between them is crucial for effective database management.
Model-level queries operate on the entire collection in the database. Methods such as findOne, find, and deleteMany are examples of model-level queries. When you call findOne, Mongoose searches the whole collection to find the first document that matches your criteria. Let's take an example:
await ProjectModel.findOne({ name: 'Bugsight' });await ProjectModel.findOne({ name: 'Bugsight' });In this case, Mongoose will search the ProjectModel collection for a document whose name field is "Bugsight". These queries are powerful but can be resource-intensive if not optimized, as they scan multiple documents in a collection.
Document-level queries, on the other hand, operate on individual documents that have already been retrieved from the database. Methods like save and deleteOne are examples. Once you've retrieved a document, you can manipulate it and then save the changes to the database. Here's an example:
const project = await ProjectModel.findOne({ name: 'Bugsight' }); // Model level
project.name = 'something_else';
await project.save(); // Document levelconst project = await ProjectModel.findOne({ name: 'Bugsight' }); // Model level
project.name = 'something_else';
await project.save(); // Document levelHere are some key differences between Model Queries and Document Queries:
- Scope: Model-level queries target a database collection, while document-level queries operate on specific, already-fetched documents.
- Efficiency: Model-level queries, being comprehensive, can be resource-intensive, whereas document-level queries are typically faster but often follow an initial model-level fetch.
- Use-case: Model queries suit broad data tasks or mass changes, while document queries are best for precise edits to individual records.
Understanding these differences helps you make informed decisions when developing database logic, ensuring efficiency and reliability in your application's data layer.
Chainable API VS. Query Parameters
Mongoose offers two primary techniques to create queries: method chaining (also known as the Chainable API) and direct application of query parameters. Each approach has its benefits and is optimal for different situations. This section will delve into the details of these techniques and guide you on when to use them appropriately.
Method chaining in Mongoose allows you to link query methods, providing control to create complex queries.
const activeProjects = await Project
.find()
.where('status')
.equals('Active')
.limit(10)
.sort('createdAt')
.select('name status')
.exec();const activeProjects = await Project
.find()
.where('status')
.equals('Active')
.limit(10)
.sort('createdAt')
.select('name status')
.exec();Conversely, query parameters are more direct and concise, requiring immediate input into the query function, making it practical for less complex queries.
const activeProjects = await Project.find({ status: 'Active' }, 'name status', { limit: 10, sort: 'createdAt' });const activeProjects = await Project.find({ status: 'Active' }, 'name status', { limit: 10, sort: 'createdAt' });For basic queries, direct parameters are clear and concise, quickly showing all the needed info. But when queries get tricky with many conditions, method chaining is the preferred choice. It makes the code easy to read and change. Performance-wise, both ways are similar since they send the same kind of request to MongoDB. So, picking one over the other depends on what feels suitable for the developer and which way is easier to manage in the code.
Mongoose Operations: CRUD and More
Most database-driven applications rely on CRUD operations to function. Mongoose provides developers with a variety of methods to streamline these operations. This section will provide an in-depth overview of Mongoose's primary CRUD operations.
Inserting Data
Mongoose offers three primary methods for adding new documents: Document::save for individual documents, Model::create for multiple documents, and Model::insertMany for batch insertions.
Saving a single document:
The Document::save method is typically used for inserting individual documents into a collection. Unlike bulk operations, this method operates on an instance of a model, providing full support for features like validation and middleware.
import Project, { IProjectDocument } from './model';
import { Model, SaveOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
save(document: IProjectDocument, options?: SaveOptions) {
return document.save(options);
}
}import Project, { IProjectDocument } from './model';
import { Model, SaveOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
save(document: IProjectDocument, options?: SaveOptions) {
return document.save(options);
}
}The Document::save method is highly customizable, accepting an optional options parameter to control aspects of the save operation. Among these options are:
validateBeforeSave(default:true): When set tofalse, the method skips all schema-defined validations, likerequiredormax.timestamps(default:true): If set tofalse, the method omits thecreatedAtandupdatedAtfields during the save process.
Refer to the documentation for the complete list of available options.
To save a project, you can use the save method as follows:
import DAO from './dao';
import Project, { IProject, ProjectStatus } from './model';
const ProjectDAO = new DAO();
const projectData: IProject = { name: 'Bugsight', status: ProjectStatus.ACTIVE };
const project = new Project(projectData);
// Save without options
await ProjectDAO.save(project);
// Save with timestamps options - this will exclude the `createdAt` and `updatedAt` fields
await ProjectDAO.save(project, { timestamps: false });import DAO from './dao';
import Project, { IProject, ProjectStatus } from './model';
const ProjectDAO = new DAO();
const projectData: IProject = { name: 'Bugsight', status: ProjectStatus.ACTIVE };
const project = new Project(projectData);
// Save without options
await ProjectDAO.save(project);
// Save with timestamps options - this will exclude the `createdAt` and `updatedAt` fields
await ProjectDAO.save(project, { timestamps: false });Saving multiple documents:
When looking to save multiple documents, Model::create comes in handy. Unlike Document::save, which operates on a document instance, Model::create is a static method invoked directly on the model.
Essentially, calling Model.create(docs) performs a new Model(doc).save() for each document in the docs array. This method, acting as a thin wrapper around the Document::save function, allows for saving multiple documents with a single function call by passing an array of objects, making it a convenient choice for bulk insertion tasks.
import Project, { IProjectDocument } from './model';
import { Model, CreateOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
saveMany(documents: IProjectDocument[], options?: CreateOptions) {
return this.model.create(documents, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, CreateOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
saveMany(documents: IProjectDocument[], options?: CreateOptions) {
return this.model.create(documents, options);
}
}The Model::create() method also accepts an options parameter that includes all options available in the Document::save() method, as well as a couple of extra ones:
ordered(default:false): If set totrueand an error occurs, Mongoose will continue processing the remaining operations in the array, reporting any errors at the end.aggregateErrors(default:false): Mongoose will, by default, throw an error at the first failed operation. It will accumulate and return a list of all encountered errors if set totrue.
Here's how to use the saveMany method to save multiple projects:
import DAO from './dao';
import Project, { IProject, ProjectStatus } from './model';
const ProjectDAO = new DAO();
const projectData: IProject = { name: 'Bugsight', status: ProjectStatus.ACTIVE };
const projectData2: IProject = { name: 'Bugsight2', status: ProjectStatus.ON_HOLD };
// You don't absolutely need this conversion if you don't plan to use the model methods
const project = new Project(projectData);
const project2 = new Project(projectData2);
// Save without options: The operation will halt and throw an error at the first failure.
await ProjectDAO.saveMany([project, project2]);
// Save with 'ordered' option: Continues saving valid documents even after encountering errors.
await ProjectDAO.saveMany([project, project2], { ordered: true });
// Save with 'aggregateErrors': Accumulates and returns a list of all errors.
await ProjectDAO.saveMany([project, project2], { aggregateErrors: true });import DAO from './dao';
import Project, { IProject, ProjectStatus } from './model';
const ProjectDAO = new DAO();
const projectData: IProject = { name: 'Bugsight', status: ProjectStatus.ACTIVE };
const projectData2: IProject = { name: 'Bugsight2', status: ProjectStatus.ON_HOLD };
// You don't absolutely need this conversion if you don't plan to use the model methods
const project = new Project(projectData);
const project2 = new Project(projectData2);
// Save without options: The operation will halt and throw an error at the first failure.
await ProjectDAO.saveMany([project, project2]);
// Save with 'ordered' option: Continues saving valid documents even after encountering errors.
await ProjectDAO.saveMany([project, project2], { ordered: true });
// Save with 'aggregateErrors': Accumulates and returns a list of all errors.
await ProjectDAO.saveMany([project, project2], { aggregateErrors: true });Performant Bulk Insertion:
The Model::insertMany() method provides an edge in efficiency over Model::create() for inserting multiple documents into a database. While Model::create() triggers individual .save() calls for each document—resulting in multiple database operations, Model::insertMany() consolidates these into a single database request. This performance boost becomes particularly noticeable during bulk inserts, such as database seeding.
import Project, { IProjectDocument } from './model';
import { Model, InsertManyOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
bulkInsert(docuemnts: IProjectDocument[], options: InsertManyOptions = {}) {
return this.model.insertMany(documents, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, InsertManyOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
bulkInsert(docuemnts: IProjectDocument[], options: InsertManyOptions = {}) {
return this.model.insertMany(documents, options);
}
}Important options to note:
rawResult(default:false): If set totrue, Mongoose returns the raw MongoDB driver result; otherwise, it returns the list of all inserted documents.lean(default:false): When set totrue, this option bypasses the hydration and validation of documents, which can be a performance booster.
For the complete list, check out Mongoose API documentation.
Usage of the bulkInsert function is straightforward:
import DAO from './dao';
import Project, { IProjectDocument, ProjectStatus } from './model';
const ProjectDAO = new DAO();
const projects: IProjectDocument[] = [];
// constructing some projects
for (let index = 1; index <= 100; index++) {
const project = new Project({
name: `Project ${index}`,
status: ProjectStatus.ON_HOLD
});
projects.push(project);
}
await ProjectDAO.bulkInsert(projects, { rawResult: true });import DAO from './dao';
import Project, { IProjectDocument, ProjectStatus } from './model';
const ProjectDAO = new DAO();
const projects: IProjectDocument[] = [];
// constructing some projects
for (let index = 1; index <= 100; index++) {
const project = new Project({
name: `Project ${index}`,
status: ProjectStatus.ON_HOLD
});
projects.push(project);
}
await ProjectDAO.bulkInsert(projects, { rawResult: true });In a single operation, we create 100 projects and return only their IDs and count of data using the rawResult option.
Fetching Data
Reading data from a MongoDB database is a frequent operation in application development, and Mongoose provides two essential methods for this: Model::findOne and Model::find. Both methods retrieve documents but differ in how they return the data.
Fetching a single document:
The Model::findOne method retrieves the first document that matches the provided query conditions. This method returns a single document or null if no match is found.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
findOne(filter?: FilterQuery<IProjectDocument>, options?: QueryOptions<IProjectDocument>) {
return this.model.findOne(filter, null, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
findOne(filter?: FilterQuery<IProjectDocument>, options?: QueryOptions<IProjectDocument>) {
return this.model.findOne(filter, null, options);
}
}The Model::findOne method takes three parameters:
filter: The criteria for document selection.projection: Specifies the fields to include or exclude in the result.options: Additional options to control the find result.
There are several useful options to use with the Model::findOne method:
lean: When set totrue, the returned document is a plain JavaScript object, enhancing performance by skipping Mongoose's document conversion.populate: Fills in referenced documents, useful when working with relational data.projection: Specifies the inclusion or exclusion of fields in the returned document.sort: Determines the sort order of documents when multiple matches exist.
Here's a basic usage for findOne():
const options = { projection: '-configuration', lean: true };
await ProjectDAO.findOne({ name: 'Bugsight' }, options);const options = { projection: '-configuration', lean: true };
await ProjectDAO.findOne({ name: 'Bugsight' }, options);In this example, findOne() searches for a project named "Bugsight" while excluding the configuration field from the result. The lean option is set to true, ensuring the result is returned as a plain JavaScript object, bypassing Mongoose's document constructor for improved performance.
Read more about populate and sort options.
Fetching multiple documents:
Unlike Model::findOne(), which returns a single document, Model::find() retrieves all documents that match the provided query. The result is an array of documents.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
find(filter: FilterQuery<IProjectDocument>, options?: QueryOptions<IProjectDocument>) {
return this.model.find(filter, null, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
find(filter: FilterQuery<IProjectDocument>, options?: QueryOptions<IProjectDocument>) {
return this.model.find(filter, null, options);
}
}The Model::find method takes the same parameters as Model::findOne. However, Model::find also offers additional options for advanced querying:
limit: Restricts the number of returned documents.skip: Skips a specific number of documents in the result set.
Here is how to use it:
const options = {
projection: '-configuration', // exclude the 'configuration' field
lean: true, // Return plain JavaScript objects, not Mongoose documents
sort: '-name status', // Sort by 'name' in descending order, then by 'status'
skip: 20, // Skip the first 20 documents
limit: 10 // Limit the result to 10 documents
}
await ProjectDAO.find({}, options);const options = {
projection: '-configuration', // exclude the 'configuration' field
lean: true, // Return plain JavaScript objects, not Mongoose documents
sort: '-name status', // Sort by 'name' in descending order, then by 'status'
skip: 20, // Skip the first 20 documents
limit: 10 // Limit the result to 10 documents
}
await ProjectDAO.find({}, options);In this example, an empty filter fetches all projects from the collection. The sort option sorts the array first by name in descending order (indicated by the preceding -) and then by status. For pagination purposes, the skip and limit options help to navigate large datasets efficiently by skipping the first 20 records and limiting the output to 10 documents.
Updating Data
Mongoose provides various methods for updating data in MongoDB collections. Key among them are Model::updateOne, Model::updateMany, and Model::findOneAndUpdate. Understanding the nuances of each will help you decide the best fit for your specific use case.
Updating a single document:
The Model::updateOne method is handy for modifying a single document based on specific conditions. This static method acts on the model, making it suitable when modifications are predicated on conditions rather than a predefined document.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions, UpdateQuery } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
updateOne(
filter?: FilterQuery<IProjectDocument>,
update?: UpdateQuery<IProjectDocument>,
options?: QueryOptions<IProjectDocument>
) {
return this.model.updateOne(filter, update, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions, UpdateQuery } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
updateOne(
filter?: FilterQuery<IProjectDocument>,
update?: UpdateQuery<IProjectDocument>,
options?: QueryOptions<IProjectDocument>
) {
return this.model.updateOne(filter, update, options);
}
}The updateOne method takes up to 3 parameters:
filter: Criteria that a document must meet to qualify for updates.update: The modifications to apply to the first found document.options: Additional options to control the update operation.
Let's demonstrate this with an example:
// Create a new project
const projectData: IProject = {
name: 'Bugsight',
status: ProjectStatus.ACTIVE,
configuration: { priorities: [{ title: 'High' }] }
};
const project = new Project(projectData);
await ProjectDAO.save(project);
// Update the newly created project
// Modifying the 'status' and push a new priority in the 'priorities' array
const filter: FilterQuery<IProjectDocument> = { name: 'Bugsight' };
const update: UpdateQuery<IProjectDocument> = {
$set: { status: ProjectStatus.COMPLETED },
$push: { 'configuration.priorities': { title: 'Medium' } }
};
// If a document is no document satisfies the filter a new one will be saved due to
// the upsert option
await ProjectDAO.updateOne(filter, update, { upsert: true });// Create a new project
const projectData: IProject = {
name: 'Bugsight',
status: ProjectStatus.ACTIVE,
configuration: { priorities: [{ title: 'High' }] }
};
const project = new Project(projectData);
await ProjectDAO.save(project);
// Update the newly created project
// Modifying the 'status' and push a new priority in the 'priorities' array
const filter: FilterQuery<IProjectDocument> = { name: 'Bugsight' };
const update: UpdateQuery<IProjectDocument> = {
$set: { status: ProjectStatus.COMPLETED },
$push: { 'configuration.priorities': { title: 'Medium' } }
};
// If a document is no document satisfies the filter a new one will be saved due to
// the upsert option
await ProjectDAO.updateOne(filter, update, { upsert: true });As you can see, we used operators like $set and $push to update the data in our example. There are quite a few operators you can use depending on the field type you want to manipulate. Check the MongoDB documentation for the complete list.
Furthermore, when set to true, the upsert option in the example denotes that MongoDB will create a new document based on the filter and updated data if our filter yields no matches.
There are a handful of options available when updating; refer to the Mongoose API for the full list.
The Model::updateOne method returns an object with some information about the operation:
{
acknowledged: true | false; // Indicates if this write result was acknowledged.
matchedCount: 0 | n; // Number of documents that matched the filter
modifiedCount: 0 | 1; // Number of the modified documents.
upsertedCount: 0 | 1; // Number of documents that were saved due to the upsert options
upsertedId: null | string; // If upsert is true, this will hold the ids of the saved documents
}{
acknowledged: true | false; // Indicates if this write result was acknowledged.
matchedCount: 0 | n; // Number of documents that matched the filter
modifiedCount: 0 | 1; // Number of the modified documents.
upsertedCount: 0 | 1; // Number of documents that were saved due to the upsert options
upsertedId: null | string; // If upsert is true, this will hold the ids of the saved documents
}Updating multiple documents:
Conversely, the Model::updateMany method stands out when modifying multiple documents based on a given condition is needed. This method, invoked directly on the model, streamlines bulk updates and simultaneously introduces consistent changes across several documents.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions, UpdateQuery } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
updateMany(
filter?: FilterQuery<IProjectDocument>,
update?: UpdateQuery<IProjectDocument>,
options?: QueryOptions<IProjectDocument>
) {
return this.model.updateMany(filter, update, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions, UpdateQuery } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
updateMany(
filter?: FilterQuery<IProjectDocument>,
update?: UpdateQuery<IProjectDocument>,
options?: QueryOptions<IProjectDocument>
) {
return this.model.updateMany(filter, update, options);
}
}Like its singular counterpart, Model::updateMany takes the same parameters, But the main difference - which is apparent by the name - is that it will update all the found documents that satisfy the filter.
const filter: FilterQuery<IProjectDocument> = { status: ProjectStatus.ON_HOLD };
const update: UpdateQuery<IProjectDocument> = {
$set: { status: ProjectStatus.COMPLETED },
$push: { 'configuration.priorities': { title: 'Medium' } }
};
// Update all documents that matchs the filter, withoum modifying the timestamp fields
await ProjectDAO.updateMany(filter, update, { timestamps: false });const filter: FilterQuery<IProjectDocument> = { status: ProjectStatus.ON_HOLD };
const update: UpdateQuery<IProjectDocument> = {
$set: { status: ProjectStatus.COMPLETED },
$push: { 'configuration.priorities': { title: 'Medium' } }
};
// Update all documents that matchs the filter, withoum modifying the timestamp fields
await ProjectDAO.updateMany(filter, update, { timestamps: false });Updating and retrieving the document:
A unique feature of Model::findOneAndUpdate is its dual nature: it modifies and retrieves a document. By default, the method gives back the original document. To receive the updated version, you need to set specific options.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions, UpdateQuery } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
updateAndFind(
filter?: FilterQuery<IProjectDocument>,
update?: UpdateQuery<IProjectDocument>,
options?: QueryOptions<IProjectDocument>
) {
return this.model.findOneAndUpdate(filter, update, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions, UpdateQuery } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
updateAndFind(
filter?: FilterQuery<IProjectDocument>,
update?: UpdateQuery<IProjectDocument>,
options?: QueryOptions<IProjectDocument>
) {
return this.model.findOneAndUpdate(filter, update, options);
}
}Model::findOneAndUpdate takes the same arguments as Model::updateOne. However, it introduces a couple of distinctive options to enhance its utility:
new: When set totrue, this option ensures the method returns the updated document rather than the original. If omitted or set tofalse, the pre-update document will be returned.returnOriginal: Essentially an alternative tonew, setting this tofalseyields the updated document.
Here's how to use findAndUpdate method:
const filter: FilterQuery<IProjectDocument> = { name: 'Bugsight' };
const update: UpdateQuery<IProjectDocument> = {
$set: { status: ProjectStatus.COMPLETED },
$push: { 'configuration.priorities': { title: 'Low' } }
};
await ProjectDAO.updateAndFind(filter, update);const filter: FilterQuery<IProjectDocument> = { name: 'Bugsight' };
const update: UpdateQuery<IProjectDocument> = {
$set: { status: ProjectStatus.COMPLETED },
$push: { 'configuration.priorities': { title: 'Low' } }
};
await ProjectDAO.updateAndFind(filter, update);By default, the result will be the document pre-update. If you aim to retrieve the modified document, set the new option to true:
await ProjectDAO.findAndUpdate(filter, update, { new: true });await ProjectDAO.findAndUpdate(filter, update, { new: true });Deleting Data
Deleting a single document:
The Model::deleteOne method targets and removes the first document that aligns with the specified conditions.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
deleteOne(filter?: FilterQuery<IProjectDocument>; options?: QueryOptions<IProjectDocument>) {
return this.model.deleteOne(filter, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
deleteOne(filter?: FilterQuery<IProjectDocument>; options?: QueryOptions<IProjectDocument>) {
return this.model.deleteOne(filter, options);
}
}For instance, to delete a project named "Bugsight":
await ProjectDAO.deleteOne({ name: 'Bugsight' });await ProjectDAO.deleteOne({ name: 'Bugsight' });Moreover, the method offers flexibility with additional options. For instance, if you wanted to first sort the documents based on the status field and then delete the first one:
ProjectDAO.deleteOne({ name: 'Bugsight' }, { sort: 'status' });ProjectDAO.deleteOne({ name: 'Bugsight' }, { sort: 'status' });The object returned by Model::deleteOne has the following structure:
{
"acknowledged": true | false,
"deletedCount": 0 | 1
}{
"acknowledged": true | false,
"deletedCount": 0 | 1
}Deleting and retrieving the document:
For scenarios where deletion and retrieval of the document are both needed, Mongoose provides the Model::findOneAndDelete method. It ensures post-deletion tasks such as logging or data processing are feasible.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
deleteAndFind(filter?: FilterQuery<IProjectDocument>; options?: QueryOptions<IProjectDocument> }) {
return this.model.findOneAndDelete(filter, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
deleteAndFind(filter?: FilterQuery<IProjectDocument>; options?: QueryOptions<IProjectDocument> }) {
return this.model.findOneAndDelete(filter, options);
}
}To use deleteAndFind(), you specify the conditions for identifying the target document:
ProjectDAO.deleteAndFind({ name: 'Bugsight' });ProjectDAO.deleteAndFind({ name: 'Bugsight' });By default, the method returns the original document before deletion. This gives you access to the entire document's data, allowing you to perform any necessary tasks.
Deleting multiple documents:
In contrast, If you want to delete multiple documents, Mongoose offers the Model::deleteMany method to cater to this need, allowing for the removal of multiple documents in a single operation. The Model::deleteMany method targets all documents within a collection that meet the given filter and removes them.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
deleteMany(filter?: FilterQuery<IProjectDocument>; options?: QueryOptions<IProjectDocument>) {
return this.model.deleteMany(filter, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
deleteMany(filter?: FilterQuery<IProjectDocument>; options?: QueryOptions<IProjectDocument>) {
return this.model.deleteMany(filter, options);
}
}For example, to delete all projects with an "Active" status:
await ProjectDAO.deleteMany({ name: 'Active' });await ProjectDAO.deleteMany({ name: 'Active' });The Model::deleteMany method returns a promise that resolves to an object with details about the operation. For example:
{
"acknowledged": true,
"deletedCount": 23
}{
"acknowledged": true,
"deletedCount": 23
}Counting Documents
Managing large datasets requires developers to understand the volume of data they're working with. Mongoose offers two primary methods to retrieve document counts from a MongoDB collection: Model::countDocuments and Model::estimatedDocumentCount. While both aim to provide the count of documents, they serve slightly different use cases and operate in distinct ways.
The Model::countDocuments method accurately records documents matching specified conditions in a collection. It's particularly valuable to count documents based on specific criteria.
import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
count(filter?: FilterQuery<IProjectDocument>, options?: QueryOptions<IProjectDocument>) {
return this.model.countDocuments(filter, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, FilterQuery, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
count(filter?: FilterQuery<IProjectDocument>, options?: QueryOptions<IProjectDocument>) {
return this.model.countDocuments(filter, options);
}
}For instance, if you want to count the number of projects with an "Active" status, you could use:
await ProjectDAO.count({ status: 'Active' });await ProjectDAO.count({ status: 'Active' });This method supports any valid query selector, which makes for flexible and precise counts. However, one thing to note is that because it scans the collection and counts each document that meets the conditions, it may be slower on vast datasets.
On the other hand, when an approximate count suffices, especially for scenarios where performance is a concern, Mongoose provides the Model::estimatedDocumentCount method. Rather than scanning the entire collection, this method fetches its estimate from its metadata. The advantage is speed, as it's considerably faster than Model::countDocuments.
import Project, { IProjectDocument } from './model';
import { Model, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
countAll(options?: QueryOptions<IProjectDocument>) {
return this.model.estimatedDocumentCount(options);
}
}import Project, { IProjectDocument } from './model';
import { Model, QueryOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
countAll(options?: QueryOptions<IProjectDocument>) {
return this.model.estimatedDocumentCount(options);
}
}To get an estimated count of all documents in the projects collection:
await ProjectDAO.countAll();await ProjectDAO.countAll();While it offers speed, Model::estimatedDocumentCount doesn't support query selectors, which will always return the estimated count for all documents.
Aggregating Data
Aggregation is a powerful capability MongoDB offers to process and transform data in collections. It allows users to execute complex data processing operations, turning them into more usable datasets.
At its core, MongoDB's aggregation operates through a pipeline. This pipeline transforms the data into stages, where each stage processes the data and passes the results to the next. It's similar to a factory assembly line, where each station or stage has a specific task, refining the product step-by-step.
Mongoose encapsulates this pipeline concept in its Model::aggregate method. This method takes an array of stages, where a distinct object represents each stage.
import Project, { IProjectDocument } from './model';
import { Model, PipelineStage, AggregateOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
aggregate(pipeline?: PipelineStage[], options?: AggregateOptions) {
return this.model.aggregate(pipeline, options);
}
}import Project, { IProjectDocument } from './model';
import { Model, PipelineStage, AggregateOptions } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
aggregate(pipeline?: PipelineStage[], options?: AggregateOptions) {
return this.model.aggregate(pipeline, options);
}
}Let's dissect an example:
await ProjectDAO.aggregate([
{ $match: { status: { $in: ['Active', 'Completed'] } } },
{ $group: { _id: '$status', count: { $sum: 1 } } }
]);await ProjectDAO.aggregate([
{ $match: { status: { $in: ['Active', 'Completed'] } } },
{ $group: { _id: '$status', count: { $sum: 1 } } }
]);The $match stage acts like a filter, passing only those documents that meet specific criteria to the next stage. It's similar to the SQL WHERE clause.
In our example, This stage ensures that only documents with an "Active" or "Completed" status will proceed to the next stage.
The $group stage groups input documents by a specified _id expression. It then applies accumulator expressions to each group, producing a single document for each group.
In the example, the status field groups the documents. The $sum accumulator is applied for each distinct status, which counts the number of documents in each group. The result will be a set of documents, each representing a unique status and its respective count.
Aggregation is a powerful tool that can transform, reorder, and even perform computations on your data in various ways. The example provided is simple, but it demonstrates the vast potential of MongoDB's aggregation framework when combined with Mongoose. By understanding and combining different stages, you can create complex queries to effectively transform and analyze their data.
Read more about the Aggregation Pipeline from the official MongoDB Documentation .
Collations
Imagine you want to treat words differently based on whether they use capital letters. For example, in a system that cares about capitalization, "BugSight" and "bugsight" are two different words. This detail is important in some software where how a word is spelled can change its meaning or functionality.
Consider you've already stored a project named "Bugsight". Now, you decide to create another project, but this time with a slightly different casing, say "BugSight". Even if your projectSchema has flagged the name field as unique, Mongoose will still permit entry. Why? MongoDB inherently treats strings as case-sensitive. This default behavior can sometimes clash with real-world scenarios, necessitating more granular control.
const projectData: IProject = { name: 'bugsight', status: ProjectStatus.ACTIVE };
const projectData2: IProject = { name: 'Bugsight', status: ProjectStatus.ON_HOLD };
const project = new Project(projectData);
const project2 = new Project(projectData2);
// Even with a unique index set on the project name, MongoDB permits both entries
await ProjectDAO.save(project);
await ProjectDAO.save(project2)
// Returns only the project named 'bugsight'
return ProjectDAO.find({ filter: { name: 'bugsight' } });const projectData: IProject = { name: 'bugsight', status: ProjectStatus.ACTIVE };
const projectData2: IProject = { name: 'Bugsight', status: ProjectStatus.ON_HOLD };
const project = new Project(projectData);
const project2 = new Project(projectData2);
// Even with a unique index set on the project name, MongoDB permits both entries
await ProjectDAO.save(project);
await ProjectDAO.save(project2)
// Returns only the project named 'bugsight'
return ProjectDAO.find({ filter: { name: 'bugsight' } });Without a case-insensitive index, your queries might yield inconsistent results and suffer from performance issues. A solution is to use $regex queries combined with the /i option. This approach ensures case-insensitive search results, regardless of how the text is stored in the database. However, a drawback is that $regex queries don't take advantage of the case-insensitive index, leading to slower performance, especially with large datasets.
Enter Collations, a must-known feature in MongoDB, enables users to apply language-specific rules for string comparison, such as considerations for letter cases. Essentially, a collation defines these intricate rules, ensuring that string comparisons adhere to the conventions and nuances of a particular language. Whether for a collection, a view, an index, or specific operations, collation ensures that MongoDB operates with precision and cultural accuracy in its string comparisons.
Let's create a collation index on both name and status fields:
const projectSchema = new Schema<IProjectDocument>(
{
name: {
//... other properties
index: {
unique: true,
collation: { locale: 'en', strength: 2 }
}
},
status: {
//... other properties
index: {
collation: { locale: 'en', strength: 2 }
}
}
},
{
//...collection's options
}
);const projectSchema = new Schema<IProjectDocument>(
{
name: {
//... other properties
index: {
unique: true,
collation: { locale: 'en', strength: 2 }
}
},
status: {
//... other properties
index: {
collation: { locale: 'en', strength: 2 }
}
}
},
{
//...collection's options
}
);You can check out directly in the MongoDB UI if the collations are created for the field:
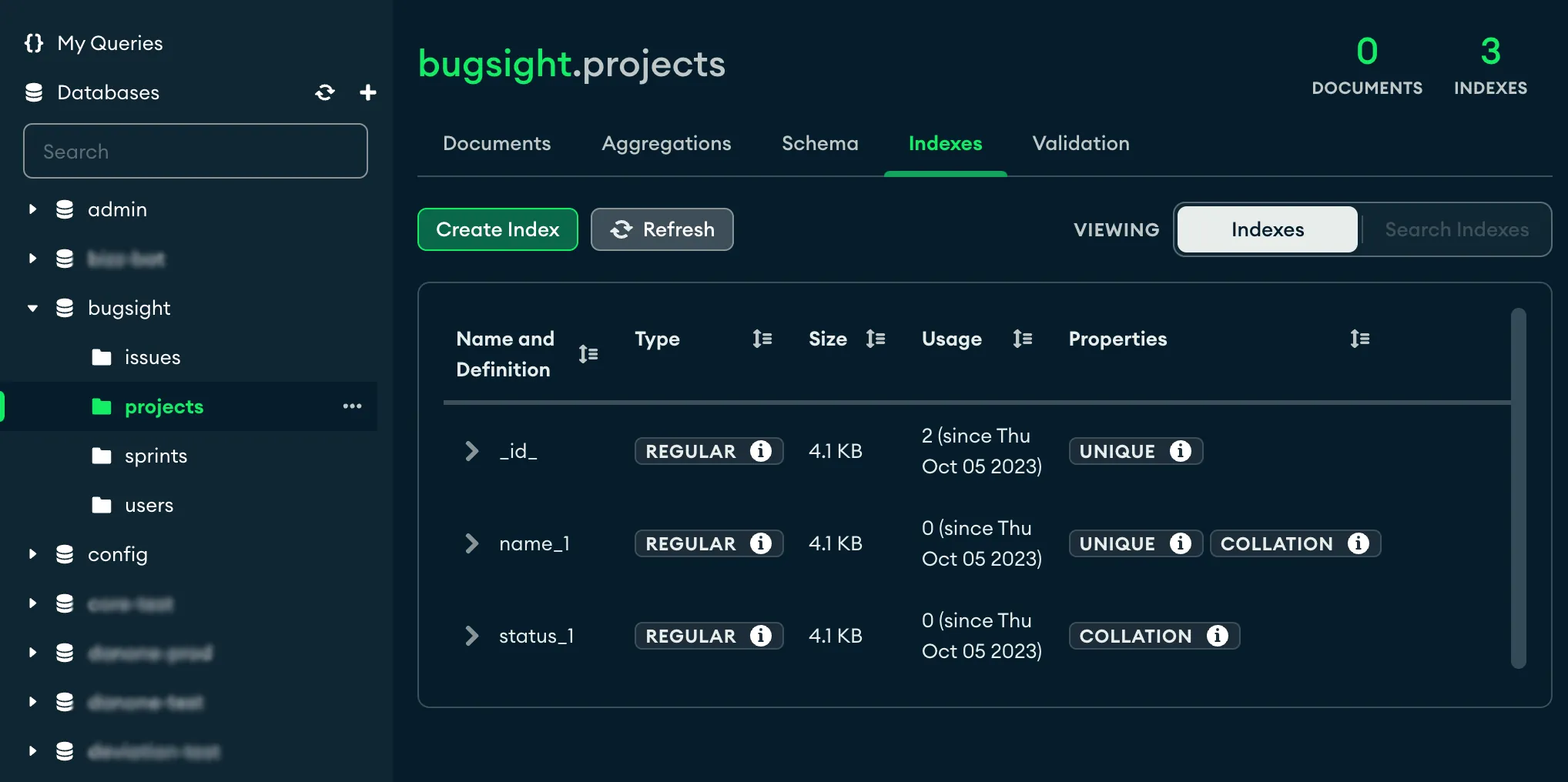
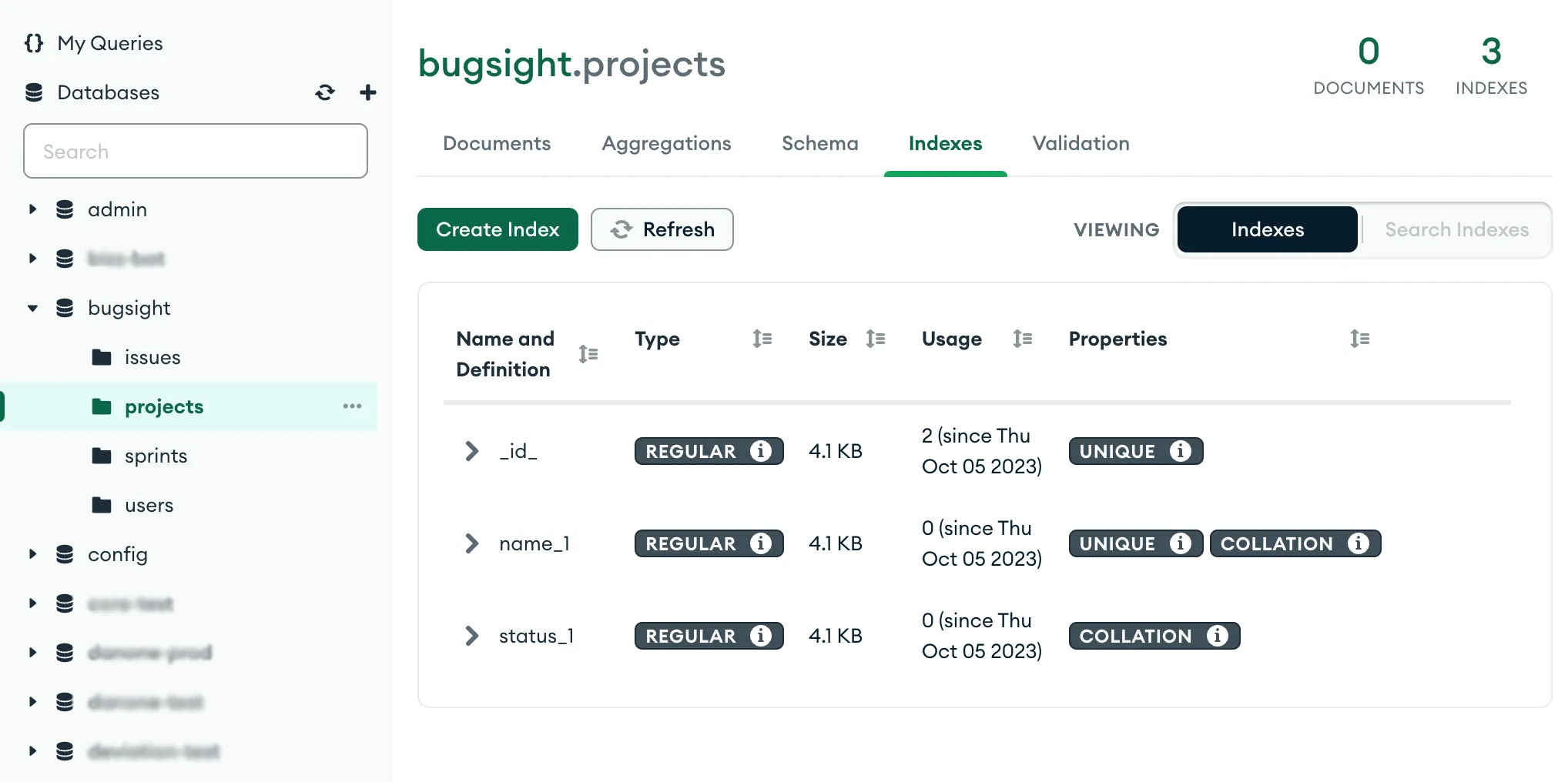
After implementing this change, executing the script will result in MongoDB raising a MongoServerError on the second call. This happens because MongoDB now recognizes both "Bugsight" and "bugsight" as identical. In the same vein, if you were to search for projects with the status "High" but you made a silly typing mistake like "HiGh", the query would still return the expected results, capturing documents with statuses like "High", "HIgh", and so forth.
Collation has a lot more use cases other than the one we saw; let's discuss some of its options:
locale(string): determines the language-specific rules for string comparison. Different languages have different conventions for sorting and comparing strings. For example, settinglocaletoenwould use English-specific comparison rules.caseLevel(boolean): When set totrue, this option enables case-sensitive comparison at the primary level of strength. This is especially useful in languages where case differences can determine word boundaries.caseFirst(string): Determines whether uppercase or lowercase letters should appear first in a sorted list. Acceptable values areupper,lower, oroff.strength(number): Dictates the depth of string comparison. It ranges from1to5, with each level introducing new comparison criteria:1: Base character comparison (e.g., 'a' vs.' b')2: Accents (e.g., 'á' vs. 'a')3: Case differences4: Variants (often language-specific)5: Identical (factors in punctuation, whitespace, etc.)numericOrdering(boolean): When set totrue, numbers in strings are sorted based on their numeric values rather than their ASCII values. For instance, "10" would come after "2" if numericOrdering istrue.
These are the most used options. Please check MongoDB Documentation for more options and details.
Understanding and setting these options can significantly enhance your MongoDB operations' efficiency and accuracy. The correct collation setup ensures that string data is compared and sorted to align with application requirements and user expectations.
Transactions
In databases, transactions ensure that a series of operations are atomic. This means that the sequence of operations is treated as a single unit, either completed entirely or not. MongoDB introduced support for multi-document transactions in version 4.0, enhancing the platform's capability to maintain data integrity across more complex operations.
Imagine a scenario where a user wants to delete a project. In doing so, two main actions must occur: the project should be removed from the database, and the sprints related to that project must be deleted too. It's vital for both these actions to either successfully complete or both fail. Having one action succeed while the other fails leads to data inconsistencies. This is where transactions prove invaluable.
A transaction belongs to a session; you must create a session before starting a transaction. Let's add a new method to the ProjectDAO class that starts a new session.
import Project, { IProjectDocument } from './model';
import mongoose, { Model } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
startSession(): Promise<ClientSession> {
return mongoose.startSession();
}
}import Project, { IProjectDocument } from './model';
import mongoose, { Model } from 'mongoose';
export default class ProjectDAO {
private model: Model<IProjectDocument>;
constructor() {
this.model = Project;
}
// ...other functions
startSession(): Promise<ClientSession> {
return mongoose.startSession();
}
}Now, to start a transaction, we need to call this method and start the transaction on the session:
const session = await ProjectDAO.startSession();
session.startTransaction();const session = await ProjectDAO.startSession();
session.startTransaction();Now we can link each operation -in our case, the project delete and the sprints delete- must be linked to the same session through the options:
const session = await ProjectDAO.startSession();
session.startTransaction();
const deletedProject = await ProjectDAO.findAndDelete({ name: 'Bugsight' }, { session });
await SprintDAO.deleteMany({ project: deletedProject?._id }, { session });const session = await ProjectDAO.startSession();
session.startTransaction();
const deletedProject = await ProjectDAO.findAndDelete({ name: 'Bugsight' }, { session });
await SprintDAO.deleteMany({ project: deletedProject?._id }, { session });Depending on the success or failure of your operations, you'll either commit the transaction, thus applying the changes, or abort it, discarding them.
try {
session.startTransaction();
const deletedProject = await ProjectDAO.findAndDelete({ filter: { name: 'Bugsight' }, options: { session }});
await SprintDAO.deleteMany({ project: deletedProject?._id }, { session });
await session.commitTransaction();
} catch (error) {
await session.abortTransaction();
}try {
session.startTransaction();
const deletedProject = await ProjectDAO.findAndDelete({ filter: { name: 'Bugsight' }, options: { session }});
await SprintDAO.deleteMany({ project: deletedProject?._id }, { session });
await session.commitTransaction();
} catch (error) {
await session.abortTransaction();
}Regardless of committing or aborting, always end the session.
try {
session.startTransaction();
const deletedProject = await ProjectDAO.findAndDelete({ filter: { name: 'Bugsight' }, options: { session }});
await SprintDAO.deleteMany({ project: deletedProject?._id }, { session });
await session.commitTransaction();
} catch (error) {
await session.abortTransaction();
} finally {
session.endSession();
}try {
session.startTransaction();
const deletedProject = await ProjectDAO.findAndDelete({ filter: { name: 'Bugsight' }, options: { session }});
await SprintDAO.deleteMany({ project: deletedProject?._id }, { session });
await session.commitTransaction();
} catch (error) {
await session.abortTransaction();
} finally {
session.endSession();
}Shared DAO
When working with multiple models such as Project, Sprint, User, and Issue, repeating the same methods across individual Data Access Object (DAO) classes for each model can lead to redundant and cluttered code. A more efficient approach is centralizing these common methods in a shared DAO class. By doing so, specific model DAOs can extend this shared class, thereby inheriting all its basic methods without unnecessary repetition.
Let's structure this solution by setting up a shared folder within the src directory. Inside, create a dao.ts file to house our shared DAO class:
import mongoose, {
Model,
FilterQuery,
QueryOptions,
UpdateQuery,
ClientSession,
InsertManyOptions,
SaveOptions,
CreateOptions,
PipelineStage,
AggregateOptions,
Document
} from 'mongoose';
export default class DAO<T extends Document> {
private model: Model<T>;
constructor(model: Model<T>) {
this.model = model;
}
save(document: T, options?: SaveOptions) {
return document.save(options);
}
saveMany(documents: T[], options?: CreateOptions) {
return this.model.create(documents, options);
}
bulkInsert(documents: T[], options: InsertManyOptions = {}) {
return this.model.insertMany(documents, options);
}
findOne(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.findOne(filter, null, options);
}
find(filter: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.find(filter, null, options);
}
updateOne(filter?: FilterQuery<T>, update?: UpdateQuery<T>, options?: QueryOptions<T>) {
return this.model.updateOne(filter, update, options);
}
updateMany(filter?: FilterQuery<T>, update?: UpdateQuery<T>, options?: QueryOptions<T>) {
return this.model.updateMany(filter, update, options);
}
updateAndFind(filter?: FilterQuery<T>, update?: UpdateQuery<T>, options?: QueryOptions<T>) {
return this.model.findOneAndUpdate(filter, update, options);
}
deleteOne(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.deleteOne(filter, options);
}
deleteAndFind(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.findOneAndDelete(filter, options);
}
deleteMany(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.deleteMany(filter, options);
}
count(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.countDocuments(filter, options);
}
countAll(options?: QueryOptions<T>) {
return this.model.estimatedDocumentCount(options);
}
aggregate(pipeline?: PipelineStage[], options?: AggregateOptions) {
return this.model.aggregate(pipeline, options);
}
startSession(): Promise<ClientSession> {
return mongoose.startSession();
}
}import mongoose, {
Model,
FilterQuery,
QueryOptions,
UpdateQuery,
ClientSession,
InsertManyOptions,
SaveOptions,
CreateOptions,
PipelineStage,
AggregateOptions,
Document
} from 'mongoose';
export default class DAO<T extends Document> {
private model: Model<T>;
constructor(model: Model<T>) {
this.model = model;
}
save(document: T, options?: SaveOptions) {
return document.save(options);
}
saveMany(documents: T[], options?: CreateOptions) {
return this.model.create(documents, options);
}
bulkInsert(documents: T[], options: InsertManyOptions = {}) {
return this.model.insertMany(documents, options);
}
findOne(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.findOne(filter, null, options);
}
find(filter: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.find(filter, null, options);
}
updateOne(filter?: FilterQuery<T>, update?: UpdateQuery<T>, options?: QueryOptions<T>) {
return this.model.updateOne(filter, update, options);
}
updateMany(filter?: FilterQuery<T>, update?: UpdateQuery<T>, options?: QueryOptions<T>) {
return this.model.updateMany(filter, update, options);
}
updateAndFind(filter?: FilterQuery<T>, update?: UpdateQuery<T>, options?: QueryOptions<T>) {
return this.model.findOneAndUpdate(filter, update, options);
}
deleteOne(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.deleteOne(filter, options);
}
deleteAndFind(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.findOneAndDelete(filter, options);
}
deleteMany(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.deleteMany(filter, options);
}
count(filter?: FilterQuery<T>, options?: QueryOptions<T>) {
return this.model.countDocuments(filter, options);
}
countAll(options?: QueryOptions<T>) {
return this.model.estimatedDocumentCount(options);
}
aggregate(pipeline?: PipelineStage[], options?: AggregateOptions) {
return this.model.aggregate(pipeline, options);
}
startSession(): Promise<ClientSession> {
return mongoose.startSession();
}
}Key Points:
- The
DAO<T extends Document>definition signifies that this class is generic. It's designed to accommodate anyTthat extends Mongoose'sDocument. This flexible design meansTcan represent any Mongoose model. - A singular private property
modelof typeModel<T>is reserved to store the Mongoose model relevant to the DAO's operations. - The constructor anticipates a Mongoose model as input, which it then assigns to the
modelproperty. This equips the DAO to operate on the provided model.
By encapsulating CRUD operations and other common methods within this DAO class, we achieve a more streamlined and uniform interaction with Mongoose models. Such centralization strengthens code reusability and enhances maintainability, a critical aspect, especially in expansive applications with consistent database interactions.
Now let's see how to extend this class in the ProjectDAO class:
import Project, { IProjectDocument } from './model';
import DAO from '../../../shared/dao';
class ProjectDAO extends DAO<IProjectDocument> {
constructor() {
super(Project);
}
// other Project-specific methods
}
export default ProjectDAO;import Project, { IProjectDocument } from './model';
import DAO from '../../../shared/dao';
class ProjectDAO extends DAO<IProjectDocument> {
constructor() {
super(Project);
}
// other Project-specific methods
}
export default ProjectDAO;The ProjectDAO class is a prime example of object-oriented programming in action, particularly the concept of inheritance. It derives its basic functionalities from the shared, generic DAO class, which offers a foundation of common database operations.
Key Aspects of the ProjectDAO Class:
- Inheritance:
ProjectDAOextends theDAOclass, inheriting its methods. By using<IProjectDocument>, it's tailored to handle Project model documents. - Constructor Use: The
super(Project)in the constructor indicates that the parentDAOclass should specifically handle operations related to theProjectmodel. - Specialization: While inheriting general operations from
DAO,ProjectDAOspecializes in theProjectmodel and can host model-specific methods.
In a nutshell, ProjectDAO exemplifies how shared functionalities can be efficiently leveraged while also introducing specialized behaviors for distinct models in a system.
Conclusion
We've learned a lot so far. From the idea behind the DAO pattern, we discovered how Mongoose can be used to communicate with our database. DAO helps keep things organized, and Mongoose queries make working with data a breeze.
But our exploration of Mongoose is far from over. As we peel back more layers of this powerful ODM, we'll find many more features. In the following article, we'll explore Mongoose's middleware and methods that can further optimize and enhance our database operations.
You can find the complete code source in this repository; feel free to give it a star ⭐️.
If you want to keep up with this series, consider subscribing to my newsletter to receive updates as soon as I publish an article.